
Projects
Motion Planning
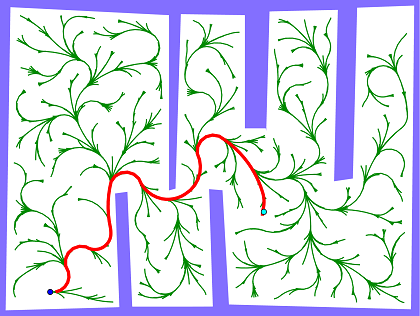
The main focus of this project is studying questions as Ackermann planning, high-dimensional planning in real-time, planning that "learns how to plan" based on experience, automatic generation of a compact representation of planning problems and others.
We work on the development of real-time planning algorithms. Recent work includes developments on Lattice-based planners, Timed Elastic Band, Hybrid A* and Rapidly-exploring random trees.
These methods have to be developed with rigorous theoretical guarantees for physical robots mainly our electric car platform to performing challenging tasks like lane changing, traffic simulation, intersection decision, parallel parking in real-world environments.
Robot Perception
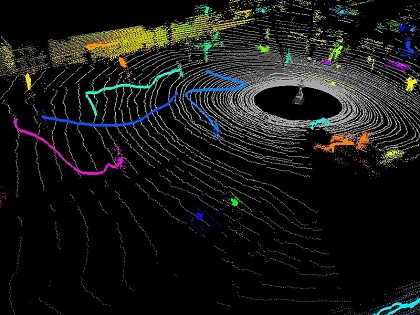
One of the major tasks which need to be accomplished for the purpose of making driverless cars a reality is the ability to detect objects in an image. In essence, the car must be able to see what is front of it. By ‘see‘, we mean the act of perception: the intermingling of the visual stimulus with our acquired memory. This is essentially the process which allows you to recognize a Coke can in a far-away shelf.
We work on various deep learning techniques for achieving human-like accuracy. End to end learning is another project in the umbrella.
Development of 3D object detection techniques is a major focus of the lab. We work on point cloud segmentation, 3D Bounding box detection, and accurate 3D object localization. Other projects include 3D Scene reconstruction and Structure from motion.
Object Detection
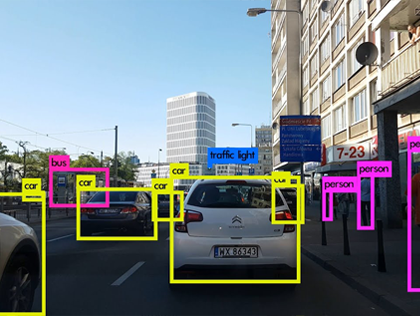
We develop vision algorithms for tasks like Pedestrian Detection, Dynamic Obstacle Tracking, Lane Detection and Road Segmentation. Specifically this project is focused on coping with the various needs of an autonomous vehicle in an diverse environment. Reliability of vision algorithms is absolutely critical as the planners trusts it to make a decision. To guarantee safety, this line of research becomes critical.
This act of perceiving can be broken down into two separate problems:
Detecting where the object lies in an image:
creating a bounding box
This is also referred to as generation of region proposals and historically this has been done by various search strategies such as the Selective Search strategy.
Identification of the object within the bounding box
This problem is just the image classification problem, i.e. given an image (which is just as big as the object), the computer must identify the image. This has been tackled to a great extent by using Convolutional Neural Networks (CNN) as I have mentioned in my post regarding MNIST digits classification.
Localization

One of the most important requirements for automating a robot is its localization. By localization, we mean that the robot must, at all times, have a fairly accurate idea about its position in a given map or environment. If a robot does not know where it is, it can not decide what to do next. In order to localize itself, a robot has to have access to relative and absolute measurements that contain information related to its position. The robot gets this information from its sensors. The sensors give it feedback about its movement and the environment around the robot. Given this information, the robot has to determine its location as accurately as possible. What makes this difficult is the existence of uncertainty in both the movement and the sensing of the robot. The uncertain information needs to be combined in an optimal way. We did so using the Extended Kalman filter algorithm, which is a kind of Bayesian filter.
Lane Navigation

Today, Driver Assistance Systems have made significant progress and several new algorithms have been designed to improve the understanding of environment surrounding the vehicle. Lane detection is one of the key issues of environment understanding. The problem is well-explored with existing approaches using varied sensors namely LIDAR (Light Detection and Ranging), radar and camera.
For the annual Intelligent Ground Vehicle Competition (IGVC) lane detection is to be done on grass and the narrower lanes (as compared to roads) present new challenges such as the case of only a single lane remaining visible. For this year’s IGVC we had implemented a support vector machine (SVM) model to detect the lanes.