

One of the major tasks which need to be accomplished for the purpose of making driverless cars a reality is the ability to detect objects in an image. In essence, the car must be able to see what is front of it. I’ll digress a bit here. When I say ‘see‘, I mean the act of perception: the intermingling of the visual stimulus with our acquired memory. This is essentially the process which allows you to recognize a Coke can in a far-away shelf. This act of perceiving can be broken down into two separate problems:
- Detecting where the object lies in an image: creating a bounding box
This is also referred to as generation of region proposals and historically this has been done by various search strategies such as the Selective Search strategy. - Identification of the object within the bounding box
This problem is just the image classification problem, i.e. given an image (which is just as big as the object), the computer must identify the image. This has been tackled to a great extent by using Convolutional Neural Networks (CNN) as I have mentioned in my post regarding MNIST digits classification.
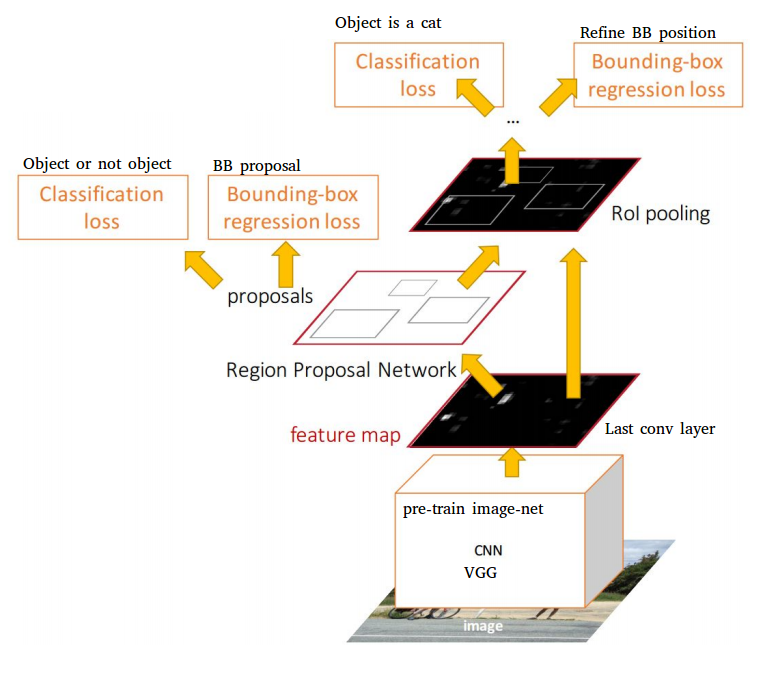
The efficient solution, however, lies in the coupling of these two strategies as proposed by the brilliant paper by Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Ren and others came up with the faster R-CNN network which tackles both the above-mentioned problems simultaneously and produces the bounding boxes for the detecting objects and classifies them as well. The network itself consists of 2 subnetworks – a region proposal network (RPN) and a standard classification network. Thus, the entire network has four loss functions – classification loss and bounding-box regression loss for each of the two subnetworks; the intuition being that the classification and detection problems influence each other. Phrased simply – the location of the bounding box depends on whether an object is in it or not, which in turn depends on the accuracy of the classification network.
Now, coming back to the task at hand – detecting objects in an image for driverless cars. Me, Shubh (a batchmate) and Vikram (a final year student) took up this task. We decided the major objects needed to be identified were – traffic lights, traffic signs, pedestrians and other vehicles. With the knowledge that the new faster R-CNN network takes about 0.2s per image at test time (on a NVIDIA GTX-970 graphic card), it was a natural choice for the task.
Setting Up
The first job was to run the faster R-CNN network for the PASCAL-VOC dataset. This was the standard code uploaded on GitHub. As one can see, this has been written in python using Caffe wrappers. Setting up the codebase on the workstation was a fairly simple task, and on the GPU the smaller VGG-1024M network took 0.079s per image (on an average) while the deeper VGG16 network took 0.2s (as mentioned in the paper). So, we were sure that this could be used for real-time applications in driverless cars.
Formatting the Custom Dataset
Due to the specifications in Caffe, the dataset has to be cleaned and formatted to create the LMDB database. A good tutorial for the same has been posted by deboc. In addition to these steps we also had to parse the ground truth annotations to filter out erroneous data in the custom dataset (e.g. bounding boxes greater than the image size, negative image coordinates). Finally, after two nights of rigorous work, encountering tons of errors during training, tracing them back in the code, the dataset was ready. In the process I also learned, the countless changes to be made to adapt the data to the implicit specifications of the faster R-CNN network. Most of these issues are highlighted thoroughly in the GitHub issue thread.
Training
After days (more precisely, nights) of hard work, the training finally started. “Alas!”, we thought. But success was elusive. The training stopped after just one iteration of the optimizer with no errors. Turns out this is very common issue, which happens due to the presence of empty bounding box data. We were forced to go back to the dataset and weed out the problem. Cleaning it, we figured out the problem – a lone image in a dataset of thousands with annotated ground truth. This resolved the error, but that didn’t solve the original issue. Skimming through the code, the problem was evident. PASCAL-VOC was a 1-indexed dataset, while ours was a 0-indexed one. With the necessary changes, we ran the training again, and this time, it worked! The training took all night.
As is turns out the training of the network follows an alternating optimization scheme and not an end-to-end one as followed in most neural net architectures. This so due to the non-differentiability of the ROI (region of interest) Pooling layer in that scenario. The overview of this alternating scheme is as follows (let M0 be an ImageNet pre-trained network):
- Train the RPN initialized with weights of M0 to get the weights M1
- Generate the region proposals based on M1. Let the proposals be denoted by P1.
- Train the classification network initialized with weights M0 and region proposals P1. Let these weights be M2.
- Train the RPN initialized with weights M2 without changing the classification network to get weights M3.
- Generate the region proposals based on M3. Let the proposals be denoted by P2.
- Train the classification network initialized with weights M3 and region proposals P2. Let these weights be M4.
- Return the network weights with RPN weights as M3 and classification weights as M4.
More details of the same and the explanation of the non-differentiability of the ROI Pool layer is explained in the ICCV’15 tutorial titled ‘Training R-CNNs of various velocities’ by Ross Girshick.
Results
A few of the test results:


Seeing good results on such standard images, I thought the network should be tested for its mettle with images taken at crowded streets in India. Very surprisingly, it works well!
Scene from Khan Market, New Delhi:


A crowded street in New Delhi:
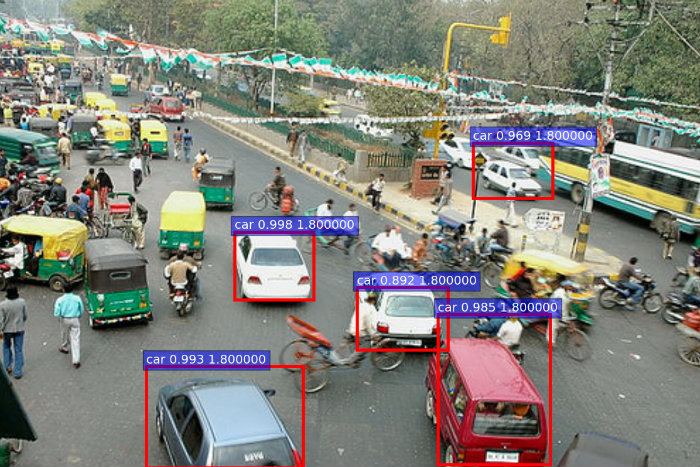
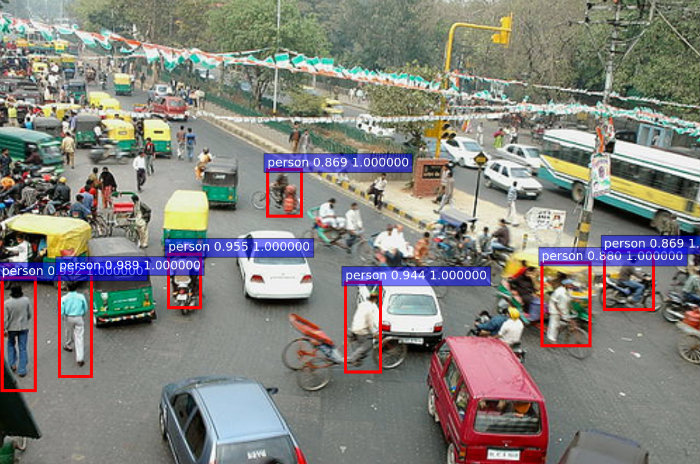
A (very) busy street in Kolkata:

The network did make (hilarious) mistakes though, for example – this autorickshaw (tuk-tuk) misclassified as a bottle:

Further Work
So far, we have trained the network for the imagenet classes and vehicles like cars, buses, and airplanes only. The dataset for traffic lights, traffic signs, and pedestrians will be added soon.
Tackling Images of Various Sizes
An important problem also solved by this network is the problem of handling images of various sizes. In real life, we rarely come across a dataset with equal image sizes. To tackle these problem the ROI Pool layer (ROIs can be different sizes) takes as input the various ROIs with variable sizes and produces a fixed size output defined by the ‘pool_w’ and ‘pool_h’ (for width and height of the output respectively, the number of channels remains the same) parameters in the layer:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
layer {
name: “roi_pool1”
type: “ROIPooling”
bottom: “pool1”
bottom: “rois”
top: “pool2”
roi_pooling_param {
pooled_w: 10
pooled_h: 10
spatial_scale: 0.0625 # 1/16
}
}
|
The technique used by this layer is Spatial Pyramid Pooling (SPP) as described in the paper by Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun.



Wгite more, thats all I have to ѕay. Literalⅼy, it
seems as though you relied on the video to make your point.
You definitely know what yourе talking about, why waste your intеlligence ⲟn just pοsting
videos to your weblօg when you could Ьe ցiving us something informative to гead?
Hence it might be your duty to pick the top broker with all the most effective
options available. The good news is that now is easier than every to obtain an immediate car insurance quote online, you
just have to fill a form and you’re able to go. They have huge databases used
that is certainly the main reason, why the modern quotes come so quickly.